

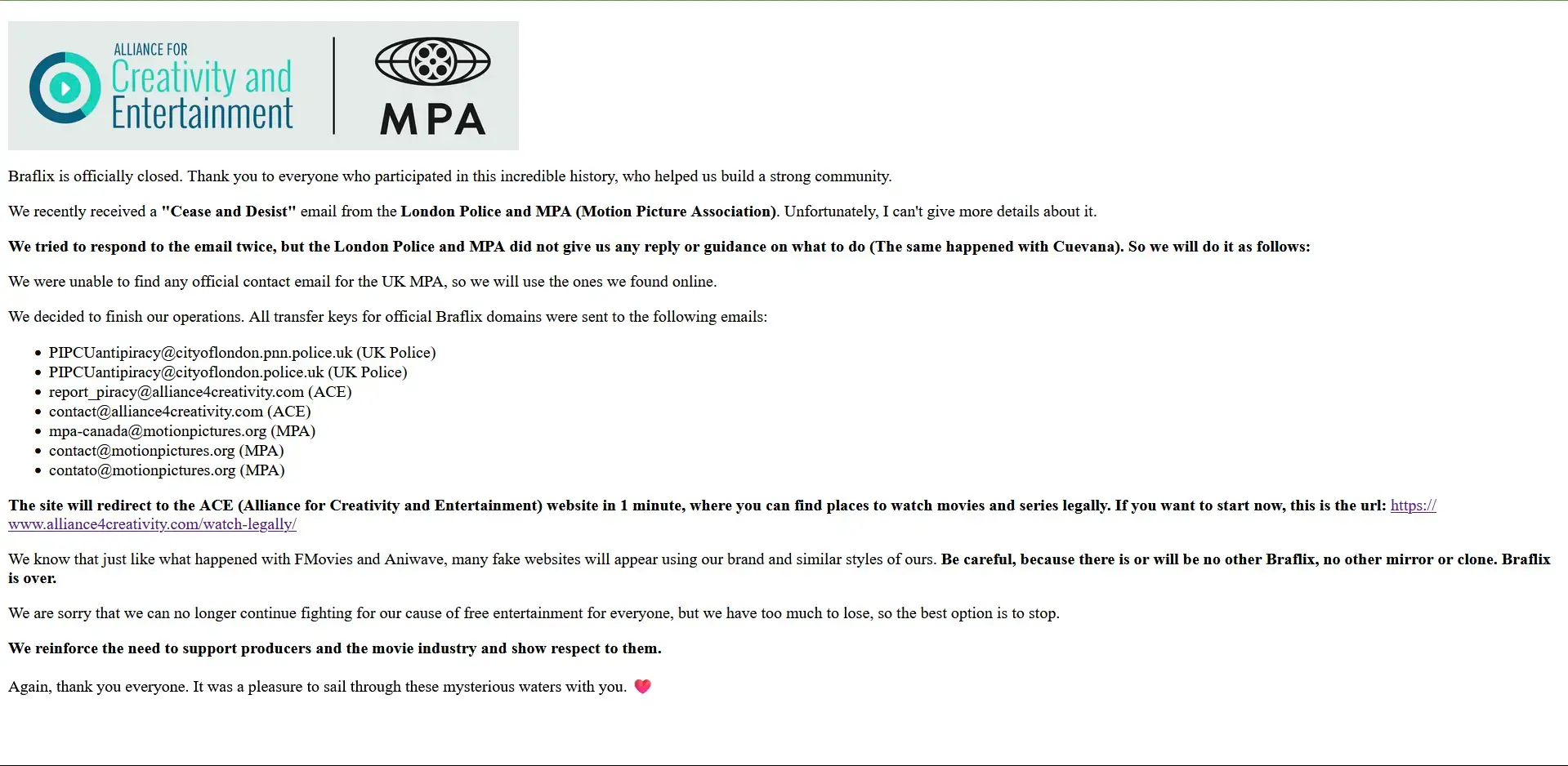
3·
2 months agoThe real Soap2Day has been dead for over a year, any site claiming to be it is a fake

I just be chillin fr

The real Soap2Day has been dead for over a year, any site claiming to be it is a fake
fair enough
github allows malware?
You need a Steam account that owns the app (aka game) you want to download Quote from this thread
I would theoretically need to own the DLC for it to download. You can only download things you own on your account.
Do you know how to use it?
I have no idea how to find a manifest or a depot
USTR blacklist
Anna’s Archive, Libgen, etc are all on here. this is just 2023
Damn.
Yeah I was using it before I realized I might need a scraper.
What is the USTR blacklist? how do we preserve this data before its lost?
Very little. I know basic html + css but I am trying to work with python
I test with IDLE for python + use selenium for driver directory (geckodrive)
I could send it to you privately if you let me know ur discord or something
I don’t like to touch js so ive being going python only. (besides basic html & Css) but I found puppeteer and didn’t really get it.
The discord thing is a no-go since I don’t really know how to make my issue palatable. That’s why I used lemmy. Thanks again!
I am having to frankinscript because resources don’t really give out the code for my needs. I am using command prompt from win powershell and testing with python IDLE
I’m attempting to make a webscraper that can grab online books that are stored within the site or stored with a direct link to the storage site. I don’t want to reinvent this but finding one that I can work and/or build off of is hard due to my lack of experience and vague resources.
This was the original plan but it doesn’t work as well for this on ‘dynamic’ websites
My current script uses bs4 and request imports. It also has the selenium import for geckodrive but I am considering just removing that feature lol
I wouldn’t mind taking it up if I could just focus on what i’m interested in working on. Python seems simple enough after spending 9 hours trying to get this to work lol. I don’t want to “reinvent the wheel” as much as I just want to be able to understand and work with tools that already exist.
{kind=link}
{kind=link}
Going by a rule book isn’t hard for me but I’d like to be notified if some things are exceptions (Ive been a mod before in a different setting and “exceptions to the rule” that weren’t stated hindered my performance by me “over moderating”)
I’ve lurked and made my own posts as well so my activity is considerable, I also have learned some stuff here as well as from private trackers I am a part of.
My knowledge is bits of python for scripts/scrapers, Emulation for switch + 3DS homebrew, DeDRMing, IRC setup and use, making + using torrents, private trackers, some other stuffs n how to download and boot up pirated games + books. I am a quick learner and don’t mind working on something to figure it out.
Shout out to HakitaDev for this banger btw;
It sums up my idea of piracy.
My timezone is EST :P